La IA al servicio del periodismo de datos. Recursos, casos y herramientas para buscar, extraer, procesar y visualizar información
La conexión entre la inteligencia artificial (IA) y el periodismo de datos no es casual. Comparten, de entrada, una misma materia prima: los datos. La IA se alimenta de grandes volúmenes de información y el periodismo de datos lleva años trabajando precisamente en la búsqueda, obtención, limpieza, análisis e interpretación de esos materiales. También hay paralelismos en su evolución: los periodistas de datos suelen estar entre los perfiles más proclives a experimentar con nuevas herramientas, lenguajes y metodologías, porque su trabajo ya exige combinar la mirada periodística con la estadística y la adaptación constante a entornos tecnológicos cambiantes.
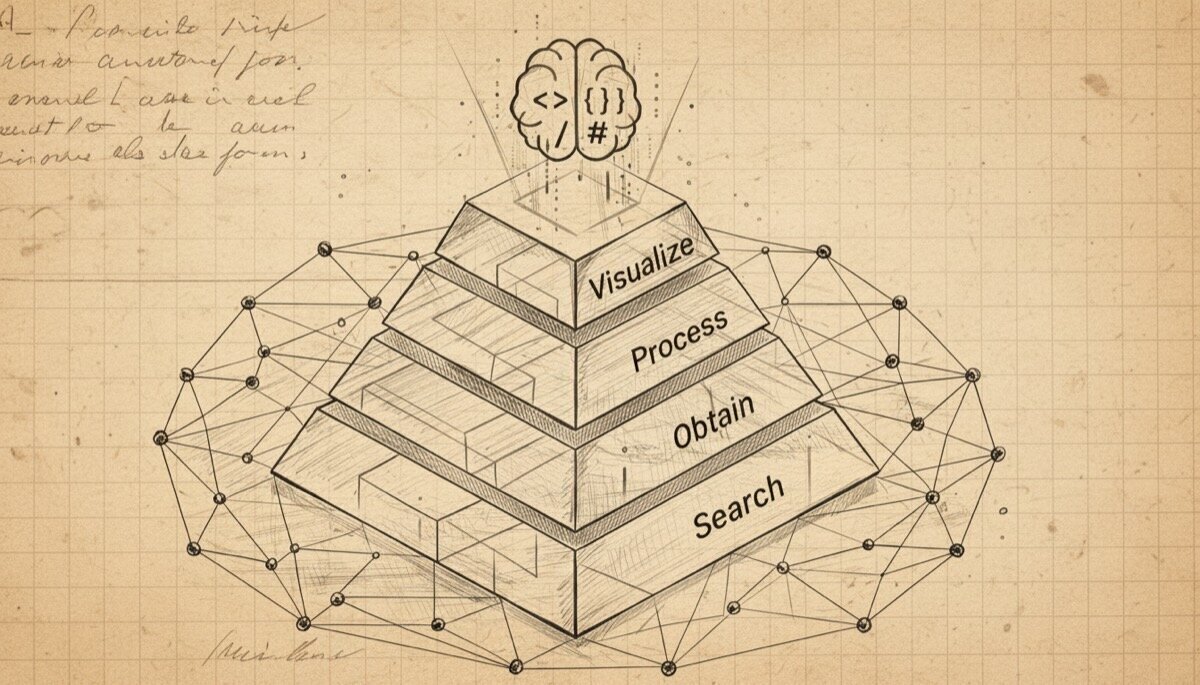
Por eso no sorprende que los periodistas de datos tengan a su disposición mayores recursos y casos de uso en tareas como localizar historias, extraer información de documentos, procesar bases de datos complejas o esbozar nuevas formas de visualización. Esta tecnología, además, resulta especialmente importante en una especialidad donde el valor no reside sólo en encontrar cifras, sino en comprenderlas, limpiarlas, conectarlas con otras fuentes y convertirlas en historias. Porque, en realidad, como ya vimos, el mayor potencial de la IA no está tanto en la publicación automática como en las fases menos visibles del proceso: la ideación, la localización de documentos, la extracción de datos y el análisis. Es decir, en usar la IA como una capa de apoyo transversal, integrada en un flujo de trabajo más amplio y siempre sometida a la verificación.
Eva Ferreras y yo ya recopilamos bastantes pistas sobre esto, a principios de 2025, en un capítulo del libro La integración de la inteligencia artificial en la comunicación digital. Pero como este panorama evoluciona a gran velocidad, merece la pena actualizar estas aportaciones. Como en ese trabajo, seguiré la ya clásica pirámide del periodismo de datos de Paul Bradshaw sobre las principales fases del periodismo de datos (y de casi todas las especialidades de la profesión): la búsqueda, la obtención, el procesamiento y la visualización. Y en todas estas fases siempre orbitará un factor común: el uso del código de programación asistido por IA permite multiplicar la potencia de todas sus aplicaciones prácticas.
Búsqueda de ideas e información
La primera utilidad de la IA para el periodista de datos aparece incluso antes de tocar un dataset. Bien utilizadas, las plataformas generalistas como ChatGPT, Gemini o Claude sirven para abrir líneas de trabajo, formular hipótesis, detectar ángulos potenciales y ordenar una investigación todavía difusa.
Pero ese uso adecuado no consiste en dejar que la herramienta divague, sino en cerrar opciones, afinar, delimitar y contextualizar. Por eso es fundamental fijar unos objetivos bien delimitados y, sobre todo, alimentarla con información de contexto precisa. Trabajar, por ejemplo, con un archivo en CSV que contenga los principales temas abordados de cada periodista (o de la competencia) puede proporcionar pistas mucho más útiles. Bien planteadas, estas consultas no generan todavía una historia cerrada, pero sí reducen el tiempo necesario para pasar de un tema genérico a un enfoque de trabajo concreto. Y eso, sobre todo en proyectos con poco tiempo o en nichos ya muy explorados, ya supone una ventaja importante.
A estas herramientas se les puede sacar más partido si se personalizan. Los GPT personalizados de ChatGPT o las Gems de Gemini permiten crear asistentes acotados a un ámbito concreto que combinen unas instrucciones más precisas, archivos de conocimiento y herramientas prediseñadas. Cuando las tareas se repiten, la necesidad de crear estos asistentes personalizados aumenta. Piensa, por ejemplo, en un buscador de textos legales publicados en el Boletín Oficial del Estado (BOE) que te ofrezca una tabla con una decena de nombres de normas, un resumen claro y el enlace directo a su publicación en PDF. Por no hablar de la posibilidad de compartir cualquiera de estas aplicaciones entre todos los miembros de un equipo.
En esta fase inicial, también resultan útiles los asistentes especializados en la búsqueda de información. Aunque su valor diferencial se haya reducido por el perfeccionamiento de las búsquedas de los chats generalistas, Perplexity sigue aportando un plus por el apoyo constante, más detallado y abundante, en el trabajo con fuentes. Y si crees como yo que la IA va a terminar subiendo el nivel de exigencia y calidad en los contenidos periodísticos, cada vez será más necesario explorar los resultados científicos. Para este tipo de búsquedas académicas, Elicit y Consensus probablemente sean las opciones más sólidas. Estos recursos permiten localizar con facilidad y precisión literatura científica, resumir artículos y extraer información de grandes volúmenes de artículos. Y sin esas “alucinaciones” de las plataformas generalistas, capaces de inventar publicaciones o incluso autores si no se les ata en corto.
Obtención de datos
Una vez definido el foco, llega uno de los cuellos de botella clásicos del periodismo de datos: conseguir la información en un formato utilizable. Ahí la IA está rebajando las barreras técnicas de forma visible. Hoy es más sencillo que nunca pedir a un asistente que escriba un script para descargar documentos, raspar una web pública o un portal, convertir tablas de PDF a Excel, renombrar archivos o limpiar un lote de datos. Y si el chat generalista no lo permite directamente, siempre es posible pedirle por ejemplo el código en Python necesario para realizar esa acción en aplicaciones tan sencillas como los cuadernos de trabajo de Google Colab.
En este punto, es necesario subrayar la potencia de los agentes. ChatGPT lo tiene integrado (en las versiones de pago) y resulta muy útil por ejemplo para descargar datos del Instituto Nacional de Estadística (INE) de manera estructurada. Una alternativa gratuita es el navegador de Perplexity: Comet. Con cuidado para evitar los prompt injections (elementos camuflados en webs para “robar” datos confidenciales), además de tareas como el resumen de las pestañas abiertas, esta alternativa al omnipresente Chrome o al Atlas de OpenaIA (solo para IOS de momento), Comet es capaz de tomar el control y descargar datos de manera automatizada. Aunque quizás la alternativa totalmente gratuita e incluso más potente es Antigravity, del que después hablaremos.
Existen numerosos casos que muestran hacia dónde puede evolucionar esta fase. DataTalk, desarrollado en el seno de la Universidad Stanford, está pensado para que los periodistas puedan consultar bases de datos complejas en lenguaje natural sin perder la trazabilidad: además de la respuesta, ofrece el código utilizado y una explicación en lenguaje llano de lo que ha hecho. iTromsø, en Noruega, desarrolló Djinn, una interfaz que recoge información de fuentes municipales (más de 12.000 PDF al mes), la ordena por relevancia y extrae información clave para detectar posibles historias. Por su parte, Hearst Newspapers desplegó Assembly en medios como San Francisco Chronicle para vigilar las plataformas públicas, transcribir centenares de grabaciones de reuniones oficiales y lanzar alertas por palabras clave a sus reporteros.
También existen avances en otra de las grandes vías de obtención de información para un periodista de datos: el uso de las leyes de transparencia. Con una de las aplicaciones personalizadas antes indicadas (GPT o Gems), sería muy sencillo diseñar un pequeño bot que, a partir de una breve frase, proporcione el borrador (quizás editable en el modo lienzo o canvas) de una solicitud formal de información. Estos recursos también pueden resultar muy útiles para la fase más ardua del proceso: la elaboración de textos o informes para reclamar o justificar peticiones públicas ante los diferentes consejos de transparencia.
La clave, en cualquier caso, radica en pensar que la IA no sólo ayuda a analizar la información ya obtenida, sino a ampliar considerablemente el volumen de materia prima accesible. Esto afecta por ejemplo a complejos expedientes administrativos, plenos municipales, actas de reuniones de equipos de gobierno, archivos judiciales, documentos filtrados o bases de datos mal estructuradas que antes se descartaban y en las que ahora se puede profundizar.
Por supuesto, conviene no perder de vista los riesgos y los límites. El hecho de que una herramienta pueda descargar o extraer información no exime de revisar la legalidad, la pertinencia y la calidad del material conseguido. Y desde luego, en los datos más crudos, hay que revisar el resultado. Porque aquí la IA también puede cometer errores.

Procesamiento de documentos y bases de datos
Casi con toda seguridad, esta fase es la más desarrollada. Los periodistas de datos siempre han trabajado corpus híbridos: PDFs, hojas de cálculo, imágenes escaneadas, audios, vídeos, correos, normas, informes o páginas web. Herramientas como NotebookLM permiten reunir todos esos materiales en un cuaderno cerrado y conversar con ellos a partir de citas internas. Esta aplicación de Google permite además generar mapas mentales, generar informes específicos o producir tablas con lo esencial, contrastar borradores con documentación. Y con uno de estos cuadernos como base, integrado en Gemini, es muy sencillo ampliar hojas de cálculo con nuevas columnas verificables. Otras herramientas específicamente diseñadas para periodistas, como Pinpoint, se orientan a encontrar historias dentro de grandes lotes de PDFs, documentos manuscritos, imágenes, correos o archivos de audio. La lógica común es clara: reducir el tiempo dedicado a orientarse dentro del caos documental.
Aquí la IA resulta especialmente útil para trabajar sobre los corpus cerrados o semiestructurados. Frente a la consulta abierta en la web, estas configuraciones reducen el margen de alucinación y hacen más fácil revisar el origen de cada afirmación. De ahí el interés de herramientas como los Artifacts de Claude o aplicaciones creadas en Google AI Studio para tareas concretas. En lugar de pedirle al modelo que “sepa de todo”, se le acota con documentos propios, instrucciones precisas y un objetivo concreto: comparar versiones de un informe, extraer cifras o nombres propios, resumir una carpeta de PDFs, construir una tabla a partir de documentos repetitivos o detectar patrones sospechosos.
Y desde luego, es imprescindible mencionar los programas más avanzados de programación asistida por IA. Antigravity (Google), Code (Anthropic) o Codex (OpenAI) permiten, mediante una simple instrucción (y algunos permisos adicionales) descargar grandes volúmenes de documentos y organizarlos en función de su contenido incluso en tu propio ordenador.
Por último, también merece la pena resaltar los avances en la IA integrada en archivos tan comunes para un periodista de datos como las hojas de cálculo. Copilot lleva meses ofreciendo utilidades notables en Excel. Pero probablemente Google le haya adelantado con claridad desde que, ahora también en España, permite introducir Gemini en Google Sheets. Sus aplicaciones darían para un artículo completo, pero al menos se puede destacar su capacidad para introducir fórmulas con lenguaje natural, combinar tablas, procesar grandes tablas e incluso introducir la IA en cada celda con una sencilla fórmula.
Los casos reales vuelven a ser útiles para entender el alcance de estos avances. Ya en 2024, el proyecto AURA, surgido en la JournalismAI Fellowship con la colaboración de medios como The Economist, Indian Express, DR (Danish Broadcasting Corporation) y Aftonbladet, se planteó precisamente transformar datos no estructurados en información contextualizada para uso periodístico. Por su parte, la BBC empleó IA en una investigación sobre la guerra de Ucrania para analizar grandes volúmenes de vídeos, imágenes, noticias y publicaciones en redes sociales. Utilizó visión artificial para etiquetar rostros, objetos y escenas, y un modelo de lenguaje para filtrar y priorizar decenas de miles de posts, según los criterios periodísticos definidos por el equipo.
En esta fase, como siempre, lo fundamental es encontrar el equilibrio entre la aplicación precisa de la tecnología y el pensamiento crítico del profesional. La idea no es delegar el análisis, sino llegar antes al punto en el que empieza el trabajo periodístico de verdad.

Visualizaciones de datos e infografías
Probablemente, esta última fase sea la más vistosa, pero la que todavía tenga más margen de mejora. En la generación de visualizaciones de datos o infografías, la IA rara vez hace por sí sola la parte más importante. Es capaz de proponer formatos, generar bocetos, sugerir rótulos, escribir código para un gráfico interactivo o transformar texto en esquemas visuales. Pero aquí el resultado raramente puede publicarse sin modificaciones importantes. Y desde luego, sigue siendo el periodista quien decide qué comparación importa, qué escala no engaña, qué contexto falta y qué lectura permite adecuadamente entender una realidad compleja.
Herramientas específicas como Napkin permiten convertir texto en formatos visuales exportables como PNG o SVG. La incorporación de la IA en herramientas tan extendidas como Canva también facilitan el prototipado de carteles o vídeos explicativos (incluyendo recursos como los gráficos de Flourish). En un nivel superior, conviene subrayar las posibilidades de las constantes actualizaciones basadas en IA de una herramienta tan versátil como Figma. Y sin duda, merece la pena hablar de recursos que facilitan aspectos antes tan complejos como el prototipado de modelos en 3D. Recursos como 3dwarehouse, Tencent HY 3D o Meshy AI están bajando la barrera de entrada a este tipo de contenidos que, hasta hace poco, requerían semanas de trabajo con software como Blender.
Ninguna de estas herramientas resuelve por sí sola la parte periodística, pero sí acorta mucho la distancia entre una hoja de cálculo y una primera propuesta visual presentable. Cuanto más fácil resulta generar una visualización, más importante es reforzar los controles. La IA puede producir gráficos plausibles, pero conceptualmente flojos; infografías vistosas, pero imprecisas; o resúmenes visuales que confunden correlación con causalidad. Por eso, en esta fase conviene reforzar algunas reglas básicas: revisar siempre el dato original, documentar la metodología, enseñar la fuente cuando sea posible y dejar claro qué parte del resultado ha sido automatizada.
Y sobre todo, en esta fase conviene recalcar una norma básica en casi cualquier trabajo con IA: no aspirar a conseguir el producto final con una sola instrucción, sino quizás una pieza específica. Por ejemplo, para una infografía compleja, rara vez será posible confeccionar todo el flujo de ideas y conceptos visuales; pero quizás sí sea posible generar, uno a uno, todos estos elementos que después el periodista tendrá que encajar.
En ese escenario, quizá la pregunta ya no sea si la IA tendrá un lugar en el periodismo de datos, sino cómo integrar esta tecnología sin perder aquello que da sentido a la especialidad. Porque, cuanto más se automaticen ciertas tareas, más valor tendrán la duda, el criterio, la verificación y la capacidad de convertir un conjunto de datos en una explicación comprensible y relevante para la ciudadanía. La IA puede ampliar el alcance del trabajo, acelerar los procesos y abrir vías antes impensables, pero el periodismo seguirá basándose, también aquí, en la mirada con la que decide qué buscar, qué comprobar y qué merece ser contado. Porque si la IA permite acelerar y optimizar algunos procesos, el periodista de datos tendrá la oportunidad de convertirse también en un “periodista de calle” para buscar las historias y los rostros entre los grandes volúmenes de información.